
Rapid Fire Abstracts
Makiya Nakashima, MSc
Research Data Scientist II
Cleveland Clinic
Makiya Nakashima, MSc
Research Data Scientist II
Cleveland Clinic
Jielin Qiu, PhD
PhD Student
Carnegie Mellon University
Peide Huang, PhD
PhD Student
Carnegie Mellon University
Po-Hao Chen, MD, MBA
Staff
Cleveland Clinic
Richard Grimm
Staff
Cleveland Clinic

Christopher Nguyen, PhD, FSCMR, FACC
Director, Cardiovascular Innovation Research Center
Cleveland Clinic
Ding Zhao, PhD
Associate Professor
CMU

Deborah Kwon, MD, FSCMR
Director of Cardiac MRI
Cleveland Clinic
David Chen, PhD
Director of Artificial Intelligence
Cleveland Clinic
Training artificial intelligence (AI) models using cardiac magnetic resonance imaging (CMR) studies is an expensive task given the relative low volume of labeled data and complexity of the image data. Current work has been focused on narrow, task specific models which rely on carefully curated datasets, resulting in bottlenecks for development of AI applications in CMR. To overcome these challenges, we propose, a multimodal learning framework which treats CMR images as videos to jointly learn embeddings between the CMR images and associated cardiologists' or radiologists' reports. We validate this framework on common downstream clinical tasks including disease classification, and image retrieval.
Methods:
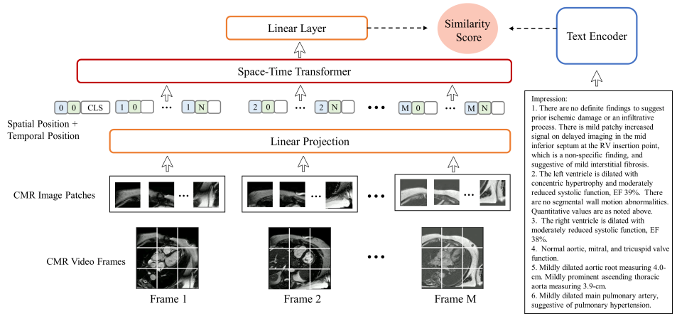
We introduce CMR Contrastive Language Image Pre-training (CMRCLIP), a text-guided video embedding for CMR. The model architecture is shown in Figure 1, which contains a visual encoder to process CMR images, and a text encoder to process text reports. The model was trained on a large, single-institution dataset of CMR studies conducted between 2008 and 2022, comprising 13,787 studies. The dataset was split into 70% for training and 30% for testing. For the zero-shot classification task, 160 studies were evaluated, with further details provided in Table 2. The model was prompted with disease descriptions, leveraging its ability to associate textual descriptions with visual embeddings without requiring task-specific training data. Image embeddings are classified based on their cosine similarity to the embedding of the textual prompts.
Results:
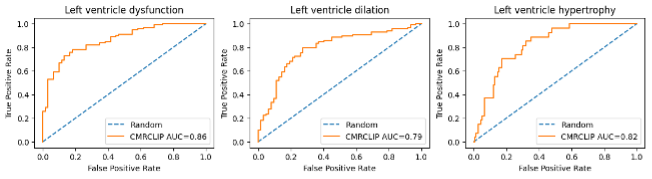
To evaluate the efficacy of the underlying representation of CMRCLIP, we evaluate the model with retrieval and classification tasks. Table 1 shows the retrieval results. CMRCLIP demonstrates remarkable retrieval performance (Video-to-Text Retrieval @ 50 = 56.4) across a wide range of CMR data formats and all metrics. Overall, we found that CMRCLIP significantly outperformed zero-shot. In the classification, our CMRCLIP model demonstrated effective classification of left ventricle dysfunction, left ventricle dilation, and left ventricle hypertrophy, achieving macro AUCs of 0.86, 0.79, and 0.82, respectively. (Figure 2).
Conclusion:
In this work, we proposed the multimodal vision-language contrastive learning framework, which enables the acquisition of Cardiovascular Magnetic Resonance (CMR) representations accompanied by associated cardiologist’s reports. CMRCLIP demonstrates significant potential for advancing AI applications in CMR, particularly in disease classification and image retrieval tasks.
Figure1: The overall architecture of our model, where the visual encoder processes sequences of CMR images and the text encoder processes the text from the “impression” section of the corresponding reports.
Figure2: Receiver Operating Characteristic (ROC) Curve with CMRCLIP zero-shot classification.
